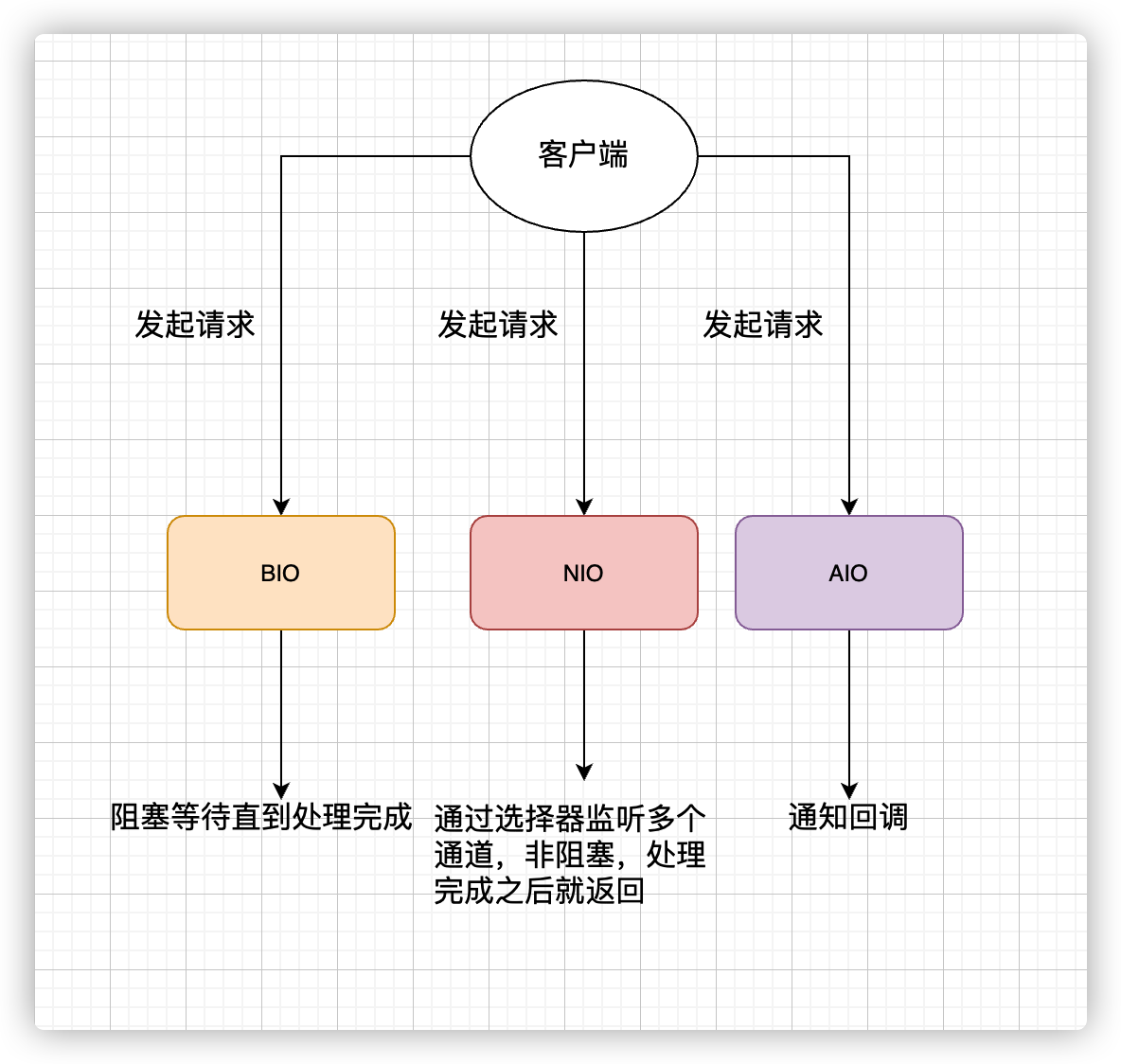
BIO 传统的阻塞式通信流程 早期的 Java 网络相关的API(java.net包)使用Socket(套接字)进行网络通信,不过只支持阻塞函数使用。
要通过互联网进行通信,至少需要一对套接字:
运行于服务器端的 Server Socket。
运行于客户机端的 Client Socket
Socket 网络通信过程简单来说分为下面 4 步:
建立服务端并且监听客户端请求
客户端请求,服务端和客户端建立连接
两端之间可以传递数据
关闭资源
服务器端:
创建 ServerSocket 对象并且绑定地址(ip)和端口号(port): server.bind(new InetSocketAddress(host, port))
通过 accept()方法监听客户端请求
连接建立后,通过输入流读取客户端发送的请求信息
通过输出流向客户端发送响应信息
关闭相关资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class HelloServer private static final Logger logger = LoggerFactory.getLogger(HelloServer.class); public void start (int port) try (ServerSocket server = new ServerSocket(port);) { Socket socket; while ((socket = server.accept()) != null ) { logger.info("client connected" ); try (ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream()); ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream())) { Message message = (Message) objectInputStream.readObject(); logger.info("server receive message:" + message.getContent()); message.setContent("new content" ); objectOutputStream.writeObject(message); objectOutputStream.flush(); } catch (IOException | ClassNotFoundException e) { logger.error ("occur exception:" , e); } } } catch (IOException e) { logger.error ("occur IOException:" , e); } } public static void main (String[] args) HelloServer helloServer = new HelloServer(); helloServer.start(6666 ); } }
客户端:
创建Socket 对象并且连接指定的服务器的地址(ip)和端口号(port):socket.connect(inetSocketAddress)
连接建立后,通过输出流向服务器端发送请求信息
通过输入流获取服务器响应的信息
关闭相关资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class HelloClient private static final Logger logger = LoggerFactory.getLogger(HelloClient.class); public Object send(Message message, String host, int port) { try (Socket socket = new Socket (host, port)) { ObjectOutputStream objectOutputStream = new ObjectOutputStream (socket.getOutputStream()); objectOutputStream.writeObject(message); ObjectInputStream objectInputStream = new ObjectInputStream (socket.getInputStream()); return objectInputStream.readObject(); } catch (IOException | ClassNotFoundException e) { logger.error("occur exception:" , e); } return null ; } public static void main(String [] args) { HelloClient helloClient = new HelloClient (); helloClient.send(new Message ("content from client" ), "127.0.0.1" , 6666 ); System.out.println("client receive message:" + message.getContent()); } }
发送的消息实体类:
1 2 3 4 5 6 @Data @AllArgsConstructor public class Message implements Serializable { private String content ; }
很明显,我上面演示的代码片段有一个很严重的问题:只能同时处理一个客户端的连接,如果需要管理多个客户端的话,就需要为我们请求的客户端单独创建一个线程。
对应的 Java 代码可能是下面这样的:
1 2 3 new Thread(() -> // 创建 socket 连接 }).start();
但是,这样会导致一个很严重的问题:==资源浪费==。
我们知道线程是很宝贵的资源,如果我们为每一次连接都用一个线程处理的话,就会导致线程越来越好,最好达到了极限之后,就无法再创建线程处理请求了。处理的不好的话,甚至可能直接就宕机掉了。
很多人就会问了:那有没有改进的方法呢?
线程池虽可以改善,但终究未从根本解决问题1 2 3 4 5 ThreadFactory threadFactory = Executors.defaultThreadFactory(); ExecutorService threadPool = new ThreadPoolExecutor(10 , 100 , 1 , TimeUnit.MINUTES, new ArrayBlockingQueue<>(100 ), threadFactory); threadPool.execute(() -> // 创建 socket 连接 });
但是,即使你再怎么优化和改变。也改变不了它的底层仍然是同步阻塞的 BIO 模型的事实,因此无法从根本上解决问题。
为了解决上述的问题,Java 1.4 中引入了 NIO ,一种同步非阻塞的 I/O 模型。