Docker命令
1 | 从公网拉取一个镜像 |
1 | 查看已有的docker镜像 |
1 | 查看帮助 |
1 | 看容器的端口映射情况 |
1 | 查看正在运行的容器 |
1 | 查看所有的容器 |
1 | 从公网拉取一个镜像 |
1 | 查看已有的docker镜像 |
1 | 查看帮助 |
1 | 看容器的端口映射情况 |
1 | 查看正在运行的容器 |
1 | 查看所有的容器 |
#Git Diff
如果 git status 命令的输出对于你来说过于模糊,你想知道具体修改了什么地方,可以用 git diff 命令。 尽管 git status 已经通过在相应栏下列出文件名的方式回答了这个问题,git diff 将通过文件补丁的格式显示具体哪些行发生了改变。
作用
此命令比较的是工作目录中当前文件和暂存区域快照之间的差异,也就是修改之后还没有暂存起来的变。化内容。
若要查看已暂存的将要添加到下次提交里的内容,可以用 git diff –cached 命令。(Git 1.6.1 及更高版本还允许使用 git diff –staged,效果是相同的,但更好记些。)
请注意,git diff 本身只显示尚未暂存的改动,而不是自上次提交以来所做的所有改动。 所以有时候你一下子暂存了所有更新过的文件后,运行 git diff 后却什么也没有,就是这个原因。
在 Java 中,JVM可以理解的代码就叫做字节码(即扩展名为 .class 的文件),它不面向任何特定的处理器,只面向虚拟机。
Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java程序无须重新编译便可在多种不同操作系统的计算机上运行。
Java程序从源代码到运行一般一下三步:
(1).java文件
JDK中javac编译
(2).class文件(JVM能理解的Java字节)
JVM
(3)机器可以执行的二进制文件
需要格外注意的是 .class->机器码 这一步:
在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。
而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT 编译器,而JIT 属于运行时编译。
当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。
而我们知道,机器码的运行效率肯定是高于 Java 解释器的。
这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。
总结:
Java虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码
,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
一般我们总会有些文件无需纳入 Git 的管理,也不希望它们总出现在未跟踪文件列表。 通常都是些自动生成的文件,比如日志文件,或者编译过程中创建的临时文件等。 在这种情况下,我们可以创建一个名为 .gitignore 的文件,列出要忽略的文件模式。 来看一个实际的例子:
1 | $ cat .gitignore |
第一行告诉 Git 忽略所有以 .o 或 .a 结尾的文件。一般这类对象文件和存档文件都是编译过程中出现的。 第二行告诉 Git 忽略所有以波浪符(~)结尾的文件,许多文本编辑软件(比如 Emacs)都用这样的文件名保存副本。 此外,你可能还需要忽略 log,tmp 或者 pid 目录,以及自动生成的文档等等。
要养成一开始就设置好 .gitignore 文件的习惯,以免将来误提交这类无用的文件。
文件 .gitignore 的格式规范如下:
所谓的 glob 模式是指 shell 所使用的简化了的正则表达式。 星号()匹配零个或多个任意字符;[abc] 匹配任何一个列在方括号中的字符(这个例子要么匹配一个 a,要么匹配一个 b,要么匹配一个 c);问号(?)只匹配一个任意字符;如果在方括号中使用短划线分隔两个字符,表示所有在这两个字符范围内的都可以匹配(比如 [0-9] 表示匹配所有 0 到 9 的数字)。 使用两个星号() 表示匹配任意中间目录,比如a/**/z 可以匹配 a/z, a/b/z 或 a/b/c/z等。
我们再看一个 .gitignore 文件的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# no .a files
*.a
# but do track lib.a, even though you're ignoring .a files above
!lib.a
# only ignore the TODO file in the current directory, not subdir/TODO
/TODO
# ignore all files in the build/ directory
build/
# ignore doc/notes.txt, but not doc/server/arch.txt
doc/*.txt
# ignore all .pdf files in the doc/ directory
doc/**/*.pdf
栈是运行时的单位,而堆是存储式的单位。
栈解决程序运行的问题,解决程序如何运行的问题,如何处理数据。
堆解决数据存储问题,数据存哪,怎么存。
Java中,一个线程,就会有一个线程栈,不同的线程执行逻辑有所不同,因此需要一个独立的线程栈。
而堆,是所有线程共有的。栈,是运行单元,里面存的信息都是与当前程序(线程)相关的。包括局部变量,程序运行状态,方法返回值等。堆只负责存储对象信息。
第一,从软件设计的角度看,栈代表了处理逻辑,而堆代表了数据。这样分开,使得处理逻辑更为清晰。分而治之的思想。这种隔离、模块化的思想在软件设计的方方面面都有体现。
第二,堆与栈的分离,使得堆中的内容可以被多个栈共享(也可以理解为多个线程访问同一个对象)。这种共享的收益是很多的。一方面这种共享提供了一种有效的数据交互方式(如:共享内存),另一方面,堆中的共享常量和缓存可以被所有栈访问,节省了空间。
第三,栈因为运行时的需要,比如保存系统运行的上下文,需要进行地址段的划分。由于栈只能向上增长,因此就会限制住栈存储内容的能力。而堆不同,堆中的对象是可以根据需要动态增长的,因此栈和堆的拆分,使得动态增长成为可能,相应栈中只需记录堆中的一个地址即可。
第四,面向对象就是堆和栈的完美结合。其实,面向对象方式的程序与以前结构化的程序在执行上没有任何区别。但是,面向对象的引入,使得对待问题的思考方式发生了改变,而更接近于自然方式的思考。当我们把对象拆开,你会发现,对象的属性其实就是数据,存放在堆中;而对象的行为(方法),就是运行逻辑,放在栈中。我们在编写对象的时候,其实即编写了数据结构,也编写的处理数据的逻辑。
堆和栈中,栈是程序运行最根本的东西。程序运行可以没有堆,但是不能没有栈。而堆是为栈进行数据存储服务,说白了堆就是一块共享的内存。不过,正是因为堆和栈的分离的思想,才使得Java的垃圾回收成为可能。
栈溢出
Java中,栈的大小通过-Xss来设置,当栈中存储数据比较多时,需要适当调大这个值,否则会出现java.lang.StackOverflowError异常。常见的出现这个异常的是无法返回的递归,因为此时栈中保存的信息都是方法返回的记录点。
JDK:
JDK是Java Development Kit,它是功能齐全的Java SDK。它拥有JRE所拥有的一切,还有编译器(javac)和工具(如javadoc和jdb)。
它能够创建和编译程序。
JRE:
Java运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java虚拟机(JVM),Java类库,java命令和其他的一些基础构件。
但是,它不能用于创建新程序。
现在我们手上有了一个真实项目的 Git 仓库,并从这个仓库中取出了所有文件的工作拷贝。 接下来,对这些文件做些修改,在完成了一个阶段的目标之后,提交本次更新到仓库。
请记住,你工作目录下的每一个文件都不外乎这两种状态:已跟踪或未跟踪。
已跟踪的文件是指那些被纳入了版本控制的文件,在上一次快照中有它们的记录,在工作一段时间后,它们的状态可能处于未修改,已修改或已放入暂存区。 工作目录中除已跟踪文件以外的所有其它文件都属于未跟踪文件,它们既不存在于上次快照的记录中,也没有放入暂存区。 初次克隆某个仓库的时候,工作目录中的所有文件都属于已跟踪文件,并处于未修改状态。
编辑过某些文件之后,由于自上次提交后你对它们做了修改,Git 将它们标记为已修改文件。 我们逐步将这些修改过的文件放入暂存区,然后提交所有暂存了的修改,如此反复。所以使用 Git 时文件的生命周期如下:
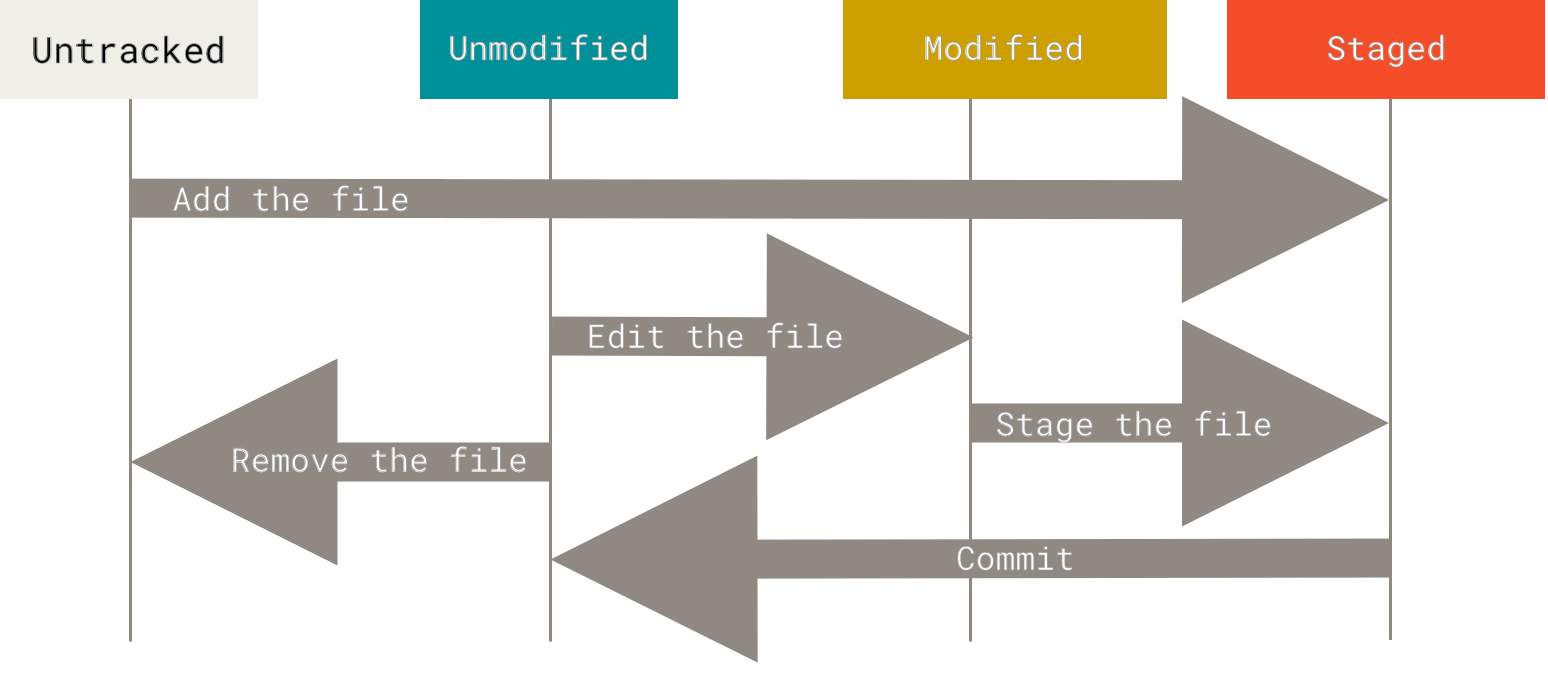
1 | 检查当前文件状态: |
这说明你现在的工作目录相当干净。换句话说,所有已跟踪文件在上次提交后都未被更改过。 此外,上面的信息还表明,当前目录下没有出现任何处于未跟踪状态的新文件,否则 Git 会在这里列出来。 最后,该命令还显示了当前所在分支,并告诉你这个分支同远程服务器上对应的分支没有偏离。 现在,分支名是 “master”,这是默认的分支名。
现在,让我们在项目下创建一个新的 README 文件。 如果之前并不存在这个文件,使用 git status 命令,你将看到一个新的未跟踪文件:1
2
3
4
5
6
7
8
9$ echo 'My Project' > README
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
README
nothing added to commit but untracked files present (use "git add" to track)
在状态报告中可以看到新建的 README 文件出现在 Untracked files 下面。 未跟踪的文件意味着 Git 在之前的快照(提交)中没有这些文件;Git 不会自动将之纳入跟踪范围,除非你明明白白地告诉它“我需要跟踪该文件”, 这样的处理让你不必担心将生成的二进制文件或其它不想被跟踪的文件包含进来。 不过现在的例子中,我们确实想要跟踪管理 README 这个文件。1
2使用命令 git add 开始跟踪一个文件。 所以,要跟踪 README 文件,运行:
$ git add README
这时候我们在运行git status查看状态:1
2
3
4
5
6$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
文件已经处于被追踪的状态了,并处于暂存状态。
现在我们来修改一个已被跟踪的文件。 如果你修改了一个名为 CONTRIBUTING.md 的已被跟踪的文件,然后运行 git status 命令,会看到下面内容:1
2
3
4
5
6
7
8
9
10
11
12$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.md
文件 CONTRIBUTING.md 出现在 Changes not staged for commit 这行下面,说明已跟踪文件的内容发生了变化,但还没有放到暂存区。 要暂存这次更新,需要运行 git add命令。
这是个多功能命令:可以用它开始跟踪新文件,或者把已跟踪的文件放到暂存区,还能用于合并时把有冲突的文件标记为已解决状态等。 将这个命令理解为“添加内容到下一次提交中”而不是“将一个文件添加到项目中”要更加合适。 现在让我们运行 git add 将”CONTRIBUTING.md”放到暂存区,然后再看看 git status 的输出:
2
3
4
5
6
7
8
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: CONTRIBUTING.md
现在两个文件都已暂存,下次提交时就会一并记录到仓库。 假设此时,你想要在 CONTRIBUTING.md 里再加条注释, 重新编辑存盘后,准备好提交。 不过且慢,再运行 git status 看看:1
2
3
4
5
6
7
8
9
10
11
12
13
14$ vim CONTRIBUTING.md
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: CONTRIBUTING.md
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: CONTRIBUTING.md
怎么回事? 现在 CONTRIBUTING.md 文件同时出现在暂存区和非暂存区。 这怎么可能呢? 好吧,实际上 Git 只不过暂存了你运行 git add 命令时的版本, 如果你现在提交,CONTRIBUTING.md 的版本是你最后一次运行 git add 命令时的那个版本,而不是你运行 git commit 时,在工作目录中的当前版本。 所以,运行了 git add 之后又作了修订的文件,需要重新运行 git add 把最新版本重新暂存起来:1
2
3
4
5
6
7
8$ git add CONTRIBUTING.md
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: CONTRIBUTING.md
git status 命令的输出十分详细,但其用语有些繁琐。 如果你使用 git status -s 命令或 git status –short 命令,你将得到一种更为紧凑的格式输出。 运行 git status -s ,状态报告输出如下:1
2
3
4
5
6$ git status -s
M README
MM Rakefile
A lib/git.rb
M lib/simplegit.rb
?? LICENSE.txt
新添加的未跟踪文件前面有 ?? 标记,新添加到暂存区中的文件前面有 A 标记,修改过的文件前面有 M 标记。 你可能注意到了 M 有两个可以出现的位置,出现在右边的 M 表示该文件被修改了但是还没放入暂存区,出现在靠左边的 M 表示该文件被修改了并放入了暂存区。 例如,上面的状态报告显示: README 文件在工作区被修改了但是还没有将修改后的文件放入暂存区,lib/simplegit.rb 文件被修改了并将修改后的文件放入了暂存区。 而 Rakefile 在工作区被修改并提交到暂存区后又在工作区中被修改了,所以在暂存区和工作区都有该文件被修改了的记录。
1.Java程序执行流程
Java技术的核心就是Java虚拟机,因为所有的Java程序都在虚拟机上运行。Java程序的运行需要Java虚拟机、Java API和Java Class文件的配合。Java虚拟机实例负责运行一个Java程序。当启动一个Java程序时,一个虚拟机实例就诞生了。当程序结束,这个虚拟机实例也就消亡。

分为编译时环境和运行时环境,很基础很重要。
有两种取得 Git 项目仓库的方法。
1 | $ git init |
该命令将创建一个名为 .git 的子目录,这个子目录含有你初始化的 Git 仓库中所有的必须文件,这些文件是 Git 仓库的骨干。 但是,在这个时候,我们仅仅是做了一个初始化的操作,你的项目里的文件还没有被跟踪。
如果你想获得一份已经存在了的Git仓库的拷贝,比如说,你想为某个开源项目贡献自己的一份力,这时就要用到 git clone 命令。
克隆仓库的命令格式是 git clone [url] 。
1 | $ git clone git@172.16.5.77:shengwangzhong/hexo-blog.git |
这会在当前目录下创建一个名为 “hexo-blog” 的目录,并在这个目录下初始化一个 .git 文件夹,从远程仓库拉取下所有数据放入.git文件夹,然后从中读取最新版本的文件的拷贝。 如果你进入到这个新建的hexo-blog文件夹,你会发现所有的项目文件已经在里面了,准备就绪等待后续的开发和使用。 如果你想在克隆远程仓库的时候,自定义本地仓库的名字,你可以使用如下命令:
1
$ git clone git@172.16.5.77:shengwangzhong/hexo-blog.git your-folder-name
这将执行与上一个命令相同的操作,不过在本地创建的仓库名字变为 your-folder-name。
Git 支持多种数据传输协议。 ssh\https\git
1 | 若你使用 Git 时需要获取帮助,有三种方法可以找到 Git 命令的使用手册: |
例如,要想获得 config 命令的手册,执行1
git help config