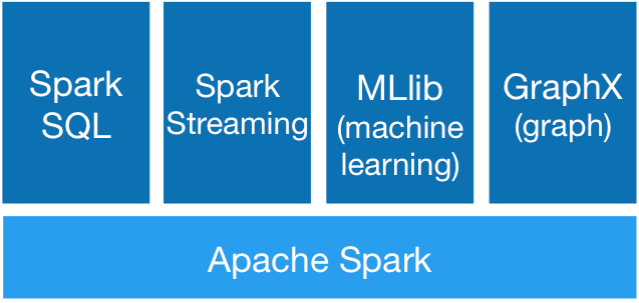
Spark的体系结构
Spark的体系结构不同于Hadoop的MapReduce和HDFS,Spark主要包括Spark Core和在Spark Core基础之上建立的应用框架Spark SQL、Spark Streaming、MLlib和GraphX。
Core库中主要包括上下文(Spark Context)、抽象数据集(RDD)、调度器(Scheduler)、洗牌(shuffle)和序列化器(Serializer)等。Spark系统中的计算、IO、调度和shuffle等系统基本功能都在其中。在Core库之上就根据业务需求分为用于交互式查询的SQL、实时流处理Streaming、机器学习Mllib和图计算GraphX四大框架,除此外还有一些其他实验性项目如Tachyon、BlinkDB和Tungsten等。这些项目共同组成Spark体系结构,当然Hadoop中的存储系统HDFS迄今仍是不可被替代,一直被各分布式系统所使用,它也是Spark主要应用的持久化存储系统。