Thread start() 和 run()
- start 和 run 方法解释:
1) start:
用start方法来启动线程,真正实现了多线程运行,这时无需等待run方法体代码执行完毕而直接继续执行下面的代码。通过调用Thread类的start()方法来启动一个线程,这时此线程处于就绪(可运行)状态,并没有运行,一旦得到cpu时间片,就开始执行run()方法,这里方法 run()称为线程体,它包含了要执行的这个线程的内容,Run方法运行结束,此线程随即终止。
2) run:
run()方法只是类的一个普通方法而已,如果直接调用Run方法,程序中依然只有主线程这一个线程,其程序执行路径还是只有一条,还是要顺序执行,还是要等待run方法体执行完毕后才可继续执行下面的代码,这样就没有达到写线程的目的。总结:调用start方法方可启动线程,而run方法只是thread的一个普通方法调用,还是在主线程里执行。这两个方法应该都比较熟悉,把需要并行处理的代码放在run()方法中,start()方法启动线程将自动调用 run()方法,这是由jvm的内存机制规定的。并且run()方法必须是public访问权限,返回值类型为void。
Java 的线程是通过java.lang.Thread类来实现的。VM启动时会有一个由主方法所定义的线程。可以通过创建Thread的实例来创建新的线程。每个线程都是通过某个特定Thread对象所对应的方法run()来完成其操作的,方法run()称为线程体。通过调用Thread类的start()方法来启动一个线程。
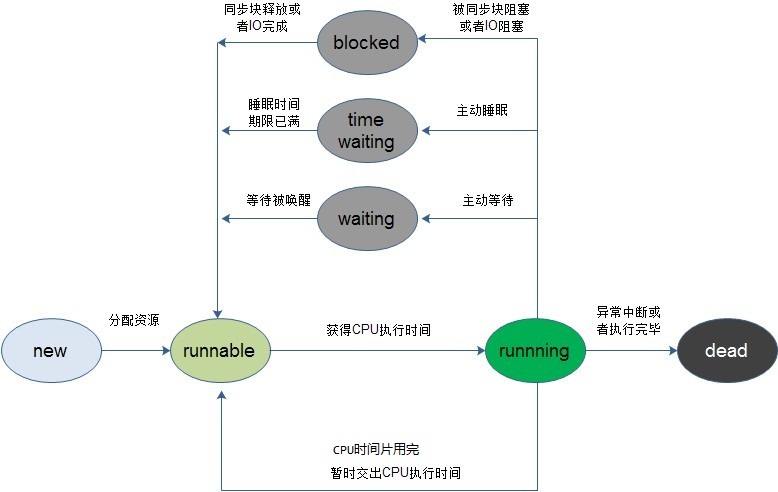
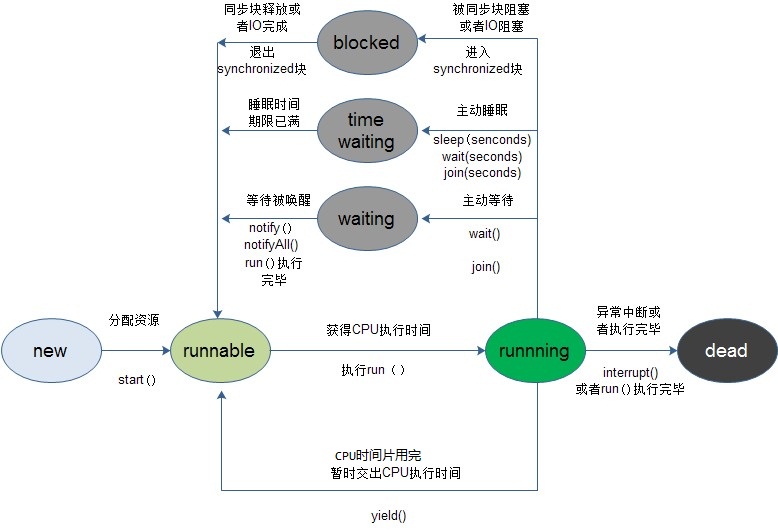
在Java 当中,线程通常都有五种状态,创建、就绪、运行、阻塞和死亡。
第一是创建状态。在生成线程对象,并没有调用该对象的start方法,这是线程处于创建状态。
第二是就绪状态。当调用了线程对象的start方法之后,该线程就进入了就绪状态,但是此时线程调度程序还没有把该线程设置为当前线程,此时处于就绪状态。在线程运行之后,从等待或者睡眠中回来之后,也会处于就绪状态。
第三是运行状态。线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进入了运行状态,开始运行run函数当中的代码。
第四是阻塞状态。线程正在运行的时候,被暂停,通常是为了等待某个时间的发生(比如说某项资源就绪)之后再继续运行。sleep,suspend,wait等方法都可以导致线程阻塞。
第五是死亡状态。如果一个线程的run方法执行结束或者调用stop方法后,该线程就会死亡。对于已经死亡的线程,无法再使用start方法令其进入就绪。
调用start()后,线程会被放到等待队列,等待CPU调度,并不一定要马上开始执行,只是将这个线程置于可动行状态。然后通过JVM,线程Thread会调用run()方法,执行本线程的线程体。先调用start后调用run,这么麻烦,为了不直接调用run?就是为了实现多线程的优点,没这个start不行。
1.start()方法来启动线程,真正实现了多线程运行。这时无需等待run方法体代码执行完毕,可以直接继续执行下面的代码;通过调用Thread类的start()方法来启动一个线程, 这时此线程是处于就绪状态, 并没有运行。 然后通过此Thread类调用方法run()来完成其运行操作的, 这里方法run()称为线程体,它包含了要执行的这个线程的内容, Run方法运行结束, 此线程终止。然后CPU再调度其它线程。
2.run()方法当作普通方法的方式调用。程序还是要顺序执行,要等待run方法体执行完毕后,才可继续执行下面的代码;程序中只有主线程——这一个线程,其程序执行路径还是只有一条, 这样就没有达到写线程的目的。
记住:多线程就是分时利用CPU,宏观上让所有线程一起执行 ,也叫并发。