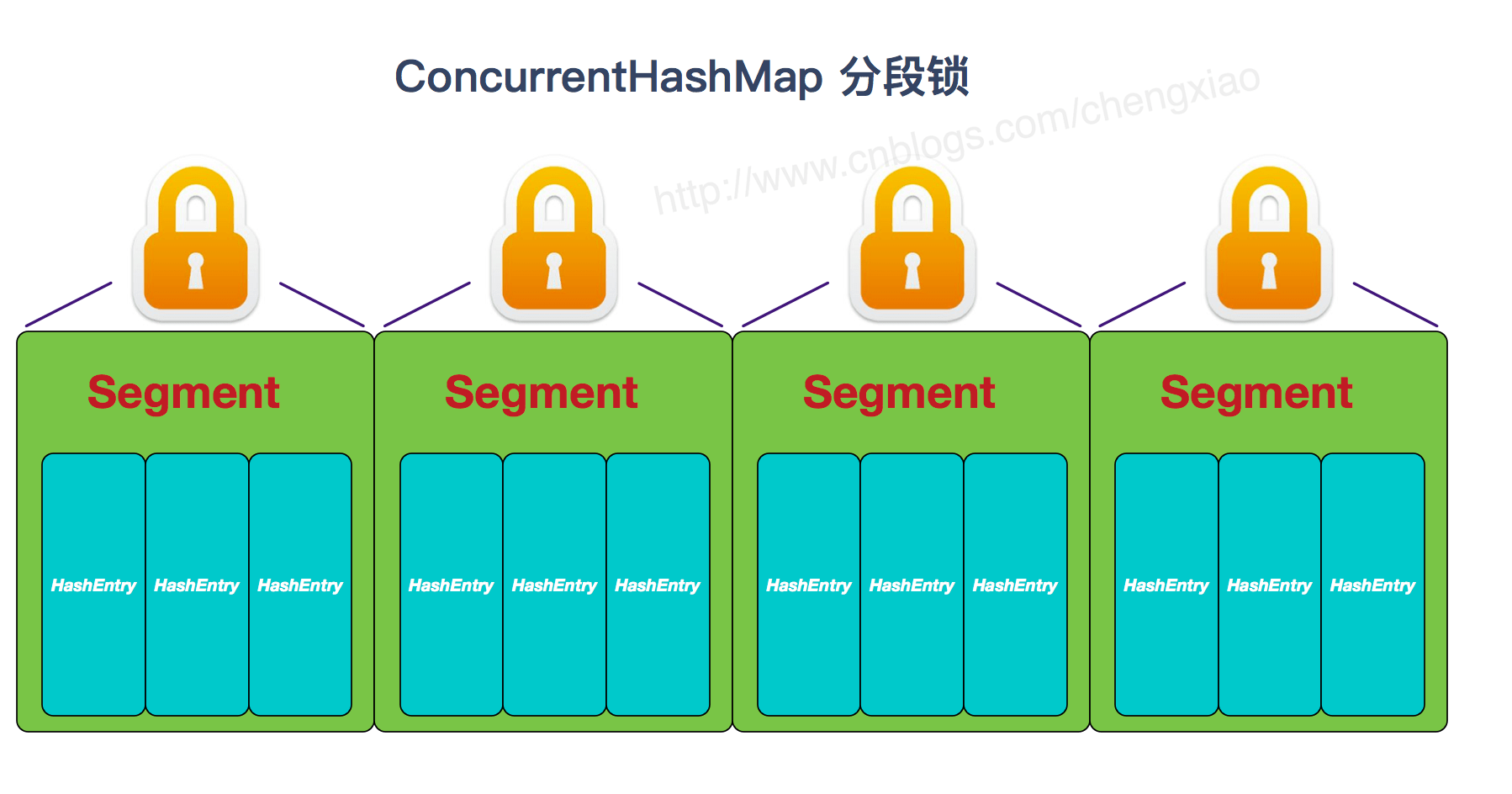
垃圾回收算法和收集器
算法
引用计数(reference counting)
古老的算法。此对象有一个引用,增加一个计数,删除一个引用减少一个引用。垃圾回收时,只用收集为0的对象。
致命问题是无法解决循环引用的问题。
复制(copying)
eg:survivor from to
此算法将内存空间分为两份。每次使用其中一个区域。(占用空间)
垃圾回收时,遍历当前使用的区域,把正在使用中的对象复制到另一个区域中。
标记清楚(Mark-Sweep)
执行分为两阶段。
第一阶段:从对象根节点开始标记所有被引用的对象。
第二阶段:遍历整个堆,把未标记的对象清除,此算法需要暂停整个应用(Stop the world)。
同时会产生内存碎片。
缺点:
1)未使用的内存空间不连续,浪费。
2)暂停整个应用。
标记整理(Mark-Compact)
执行分为两阶段。
第一阶段:从对象根节点开始标记所有被引用的对象。
第二阶段:遍历整个堆,把未标记的对象清除,同时把存活的对象压缩到一块,顺序排放,避免碎片问题。
避免了复制算法的空间问题。